Hello all,
is here anybody experienced with using Japanese in the Nextion displays or Editor?
I want to display some special characters but I am not really succesful. I am desperate.
I am using standard Shift-JIS encoding which is only present in the Editor. I read that Japanese characters are 2-byte alligned. I want to display this character: ソ https://www.codetable.net/hex/ff7f
I think that one byte represents an escape character. It is not possible to send all existing characters to the Nextion. You can’t even send hex code, e.g.: t0.txt="\x48"
What to do with it?
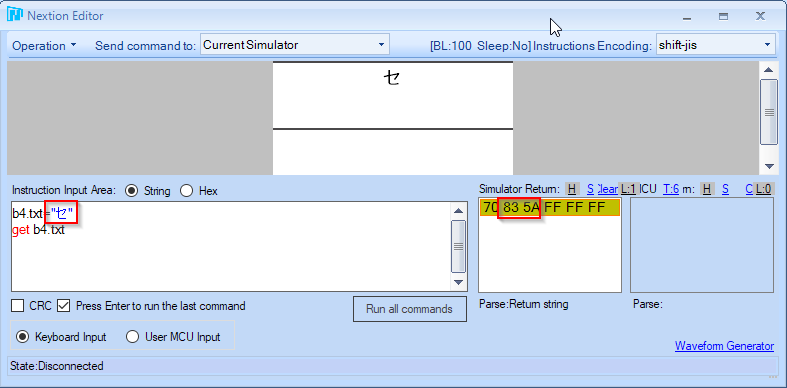
Can you display other characters in Shift-JIS, like セ ゼ or ゾ タ?
I can display those but don’t succeed with ソ, which is odd…
Any chance you can use UTF-8 encoding? You’ll have to use USART Editor to generate the font, but you can then use that .zi file in Nextion Editor as well. I can display the ソcharacter using UTF-8 encoding/font.
Nextion doesn’t do any special encoding escape sequences, only 3 special sequences are defined in the reference -see below-. It expects the bytes in the same encoding as the font you’re using for that object. If you paste the text in the txt property of a field, the editor will convert it to the proper bytes.
You can get/set the bytes in debug mode using: get t0.txt. The HEX string returned will start with 70 and end with FF FF FF. The bytes in between are the byte representation of your string:
I think ソ should be HEX bytes “83 5C” but I can’t get that to show. To me it seems a bug in the shift-jis implementation… hence my advice to try UTF-8.
Note that byte 5C is the backslash that is also used in 3 predefined escape sequences. It seems to be throwing off the decoder:
Character escaping is performed using two text chars: \r creates 2 bytes 0x0D 0x0A, \” 0x22 and \ for 0x5C
Edit:
After some more research, I found that you need to add a backslash after the character, which is counter-intuitive to say the least:
What happens is the bytes for ソ are 83 5C, but 5C is the backslash and the escape character. Since the following quote would be escaped, you need to add another backslash to make the escape sequence correct…
Seems that the decoder is not at fault, but the encoder should have added that additional backslash which is required.
Hello fvanroie,
thank you very much for the answer.
Yes, other characters have been displayed without problems in Shift-JIS encoding.
I knew that the problem is related with 0x5C character (\). However I was not able to find workaround or solution.
Sorry for the bad link - it was halfwidth version.
Here is better: https://www.codetable.net/name/katakana-letter-so
And here even more useful: https://www.wikiwand.com/en/So_(kana)#/Other_representations
b4.txt="ソ\"
is good workaround - this is the thing I can work with further. Even if I cannot see it untill I run the simulator :-(.
I don’t know how to use UTF-8. Can you advise? Can it help?
I cannot display the character if I enter this in the Nextion IDE (Attribute). If I enter ソ\ to the txt field, error message appears but then the compilation is successful and ソ\ is displayed (the backslash is visible). This is not good.
Also I am not sure how to send the japanese characters from the MCU to the Nextion in the future. I did not try it. I will decide if it would be better to have the strings saved in the Nextion or in the MCU memory and send the chosen strings through the UART (more universal).
Both UTF-8 and Shift-JIS can display Katakana characters. Basically it’s a design choice, so you need to weigh the pro’s and con’s.
Shift-JIS:
Officially supported in Nextion Editor
Contains this bug.
Font can be generated in nextion Editor
Cannot display ソ in the editor nor any other multi-byte characters that end in 5C like Ы, 噂 and 浬
Only for Japanese, if you want to support other scripts you need additional fonts with different encoding
2 byte characters
UTF-8:
Not officially supported (yet), but in my testing I found it just works fine.
Doesn’t contain the 5C sequence in multi-byte characters, so doesn’t have the bug.
Font has to be generated in another program
Can display ソ in the editor
Supports other languages and scripts, making it more versatile
Is the de-facto encoding used in most modern applications
UTF-8 encoded Japanese text uses more bytes, as the characters use up to 3 bytes.
Unless you really need official support from Nextion (which is both pricey and worthless at the same time), the only drawback I see is generating the font outside the Nextion Editor…
For the MCU it’s all just byte array’s. There shouldn’t be any issue with storing and sending the bytes over UART, just make sure to escape the byte sequences with the extra slash as needed.
If you decide to use UTF-8 you need to store the text in that encoding instead of Shift-JIS encoding…
Hello,
the problem is not sufficiently solved.
UTF-8 is not supported now in the 0.58 editor as fvanroie wrote. I am not able to find .zi font generator with UTF-8 and antialiasing support and I am not too advanced programmer.
It is not possible to set the command (e.g. t0.txt=“ガス”) with japanese characters to the Touch event or Preinitialize event. After this the characters ?? are displayed in the simulator.
If I write the command e.g. t0.txt=“ソ\”, then error appears:
Error:Improper use of escape characters:t4Soft.txt=“ソ¥”( Double click to jump to code)
Error:Compile failed! 1 Errors, 0 Warnings,
So simulator cannot be run.
To better understand my goals:
I need to be able to change text in the text field without MCU (in the Nextion) by Touch action (Event).
(Representation of the Yen sign ¥ is clear, it is backslash \ in Shift-JIS, 0x5C character)
Not sure what the remaining problem is, but it’s working fine here. Did you set the font of the t0 field to the Shift-JIS font?
I can put this code in the Touch Press/Release Event code and it works fine:
b5.txt="ガス"
b4.txt="ソ\"
Try copy/pasting that in your project.
The ¥ character code is also 5C, again the same as a backslash in ASCII:
In JIS X 0201, of which Shift JIS is an extension, the yen sign has the same byte value (0x5C) as the backslash in ASCII. This standard was widely adopted.
This poses an even bigger problem, because escaping the Yen symbol will result in a backslash character being show in Nextion Editor… Only ‘out-of-the-box’ solution for the Yen symbol is to use its double wide variant instead:
b4.txt="ソ\¥"
Or you need to edit the font and replace the \ character with a Yen symbol instead, which is actually what the standard Shift-JIS character at position 5C is. We’re working on a Font Editor, but it’s not done yet.
The Shift-JIS implementation is clearly broken in v0.58 and I would not use it in this broken form. I can’t imagine any Quality Control was done on this “feature”. This will keep giving you problems which are very hard to troubleshoot…
I finally found the solution. However this only adds more problems. See further:
I have to change Character Encoding to Shift-JIS in the Device setting (it is right under the Display direction) in the Nextion Editor. When I change the text with japanese characters in the Event, then when I start the simulator and then when the event is started, japanese text is displayed succesfully.
This is not the end.
I have to implement more languages. What if I want to implement Russian, German, Czech, …
It seems it is not possible as I would have to change the Encoding of the Device before every command with special foreign characters. Otherwise I would see only ??? (question mark) characters.
I’m afraid that only UTF-8 support in the editor would solve it.
Nextion can handle UTF-8 text and fonts, even though you can not select the utf-8 encoding in the Panel Properties, debugger or Font Generator.
There are actually 4 places that (can) have a different text encoding:
The Panel Properties :
This is used to encode all text in Event Scriptblocks.
The Text Object .txt attribute:
This is used to encode text using the encoding of the associated font.
The Debugger :
This is used to encode text string in the debugger.
The MCU :
Any encoding, but the encoding of the text sent should match the encoding of the associated font.
Using an UTF-8 font you can just type unicode characters in the Editor .txt attribute and it will get encoded correctly, no need for extra escape characters:
Also via the MCU is another way to display strings that are utf-8 encoded. If you use UTF-8 for all your strings, the texts can be stored on the MCU in UTF-8 without a need for any other encodings. It will make the internationalization of your project much easier.
Since the fonts also need to be UTF-8, you don’t need to change the .font property on your textfields to switch encodings because utf-8 can handle all language scripts.
This forum is in no way affiliated with NEXTION®, ITEAD STUDIO®, TJC®, or anyone else really. All product names, logos, and brands are property of their respective owners. All company, product, and service names used in this website are for identification purposes only. Use of these names, logos, and brands does not imply endorsement from the respective rights holder(s).
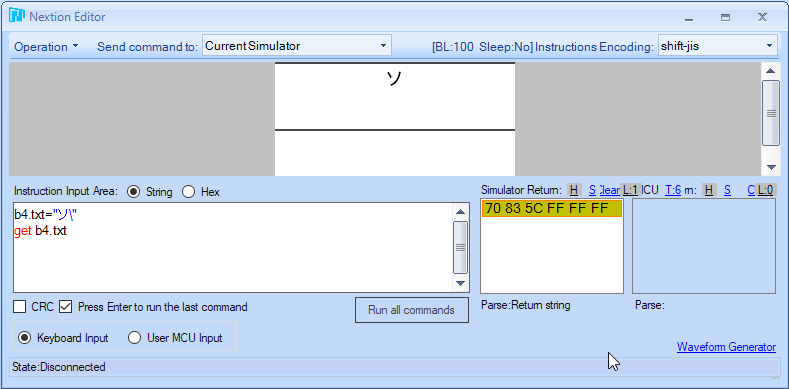
 - this is the thing I can work with further. Even if I cannot see it untill I run the simulator :-(.
- this is the thing I can work with further. Even if I cannot see it untill I run the simulator :-(.